NumPy
NumPy is one the most important package and is used extensively in Data Science and also find applications across different domains like scientific computing, engineering disciplines, finance, and so on.
Why NumPy came into the picture?
In many domains, we work with high-dimensional arrays which contain numbers as the data items, for example, say a bio-chemist is working on protein folding, and he would like to analyze different ways in which proteins fold in enzymes; then the number of such folds is typically very large and storing data and processing such data requires high dimensional numerical arrays.
Or if you’re a stockbroker and are interested in analyzing stock markets moving up and down let’s say high resolution, every minute you have data points across multiple stocks, multiple markets, typically this also requires high dimensional data stores.
Say a company like Amazon wants to work on customer’s data, which customers on which date bought what item, browsed which page, and so on, then this can be extracted as large dimensional numerical arrays.
Even if it is just data processing for instance consider taking an image on your smartphone and then processing it with a filter, this involves going through the image which itself is a large dimensional array and doing lots of operations very efficiently across slices of this array.
In Deep Learning, typically the models are very large let’s say for computer vision, image processing or natural language processing, then a model can have millions of parameters and multiple such models are usually analyzed, and so on and this again requires a high dimensional data to be processed efficiently.
So, we are looking for ways to store and process high dimensional arrays efficiently.

We have already discussed and seen other data types such as lists, sets, tuples, dictionaries and you must be wondering any of these can be used to store such high dimensional arrays, for example, you can have a list of floating-point numbers which then act as a one-dimensional array, you can also have a list of lists whereby you can store a matrix where every row becomes one list and coming together of many such rows would make another list.
Looks like we actually some sort of machinery to implement the high dimensional arrays and also to process them(say iterating over a list of lists to find the minimum value), but in practice, this is very inefficient compared to the expected performance.
And by expected performance what we mean is — say you buy a processor from Intel, it would have a rated performance as some number of GigaHertz(which means how many times in a given second would the processor clock cycle go up and down) and something in GigaHertz means that you’re having 10⁹ or more ticks in the clock every second. And typically in these efficient processors, in a given clock tick, the processor can run one or more multiplications, so with this rough sense, you can compute how much you should expect from hardware that you buy.
And it turns out that if you implement lists to do the operations and measure the time taken, you’ll find 10x to 100x the time taken. And this can be very significant when working with large dimensional arrays.

Let’s see why this performance impact lists.
First, lists are designed for a broader purpose, they can store heterogeneous data but when we are particularly working with numerical arrays, we want the storage and processing not to have this overhead of type checking which is required with lists.
The second reason is that they don’t exploit available hardware mechanisms for storing lists and processing lists efficiently. In most systems, it is fairly clear how we store data, so you would have something called DRAM which stores temporary data used by your programs, and DRAMs have a particular way in which they can be used more efficiently using burst access.
Now lists are not fully optimized to ensure that when I’m accessing a list in a particular way, I completely benefit from the burst that I can get in accessing DRAMs.
Similarly, when doing operations on different items of lists, most processors have something called vectorization where multiple computations can be done in one go, and lists implemented in Python do not fully exploit this.
In simple terms, we can say that there are mechanisms both in the storage and processing at the hardware level which are not fully exploited in the way we process lists.

This is where NumPy comes in. It’s a package that tries to efficiently process and store high dimensional arrays.

The way NumPy intends to bring improvements can be understood from three levels:
At the hardware level, the first thing NumPy does is that it takes advantage of the DRAM technology to ensure that if we typically access the arrays, it would benefit from what is called DRAM burst access and thereby have a high throughput. NumPy also provides a way in which we can store high-dimensional arrays onto files and also load them back and it turns out that the stored files are very small and hence we have an efficient way to bookmark data onto the disk.
At the programming level, NumPy avoids this type-checking overhead, because NumPy has homogeneous data types, it can ensure that the type-checking which is very expensive is not done every time there is an operation to be performed on an item of the array. It also enables other packages to use the NumPy arrays as an efficient data interface.
At the user’s perspective level, NumPy provides this interesting idea of broadcasting operations. It is this idea of having operations on an array of different sizes and how Python can automatically expand one of the operands to match the other’s size. It also provides an implementation of many functions across linear algebra, statistics, and so on.

Comparing performance with lists:
Let’s say we have a list of 10⁸ numbers and we want to square each of the numbers and store back in the list at the same index. We use the magic command ‘%%time’ to measure the time it takes to run the code(it runs the code only once and report its time taken).
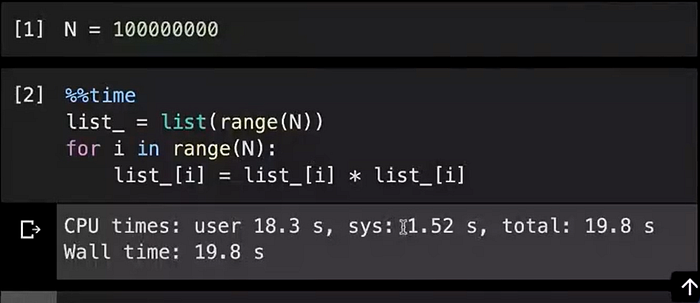
It took about 20 seconds to complete using the list data type, what we are doing here is 10⁸ useful operations(we’re doing one operation for each item of the list, of course, there are other things that are required for example the addresses of the item in the list, we need to increment the loop counter ‘i’ and so on).
Even with lists, we can improve the performance by writing things differently, for example, the same logic as above but implemented in a different way would be:
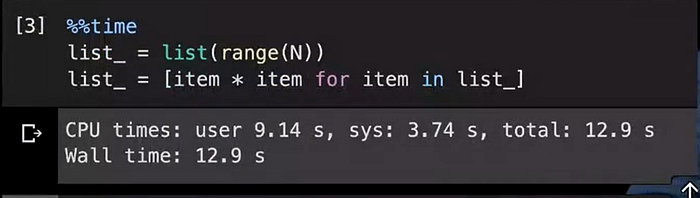
So, this way was faster compared to the previous one, so it completed in just 13 seconds(about 1/3rd time faster), this is significant because if you try to buy a 33% faster processor, you have to spend a lot of money but if you carefully tune your software, in the above case, a very small change in how we get a new list, we’re getting much higher performance.
There is one other way of implementing this same logic and is more efficient in the above two cases. Here, in this case, the new item is going to be created by mapping a function to each item of the original list.
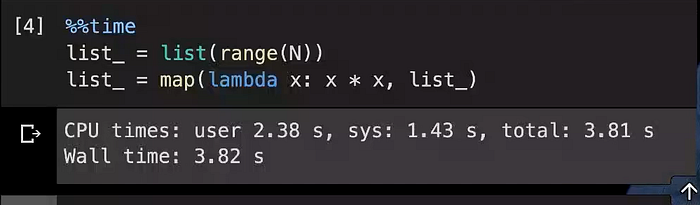
This runs significantly faster, so we are getting almost 5x time the performance compared to the first implementation by just changing the way we are doing operations across the list.
Let’s understand it taking the example where we are summing up all the values in the list.
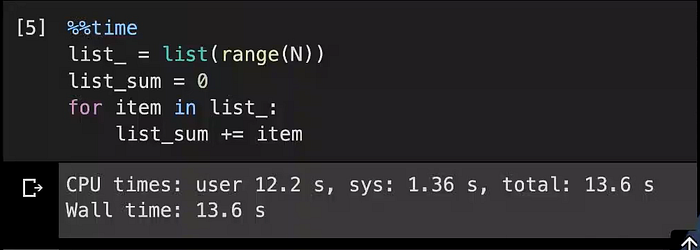
It takes almost 13 seconds to add up 10⁸ numbers. We can compute it using the in-built ‘sum()’ function as well. Let’s use it and compare the time it takes in that case.
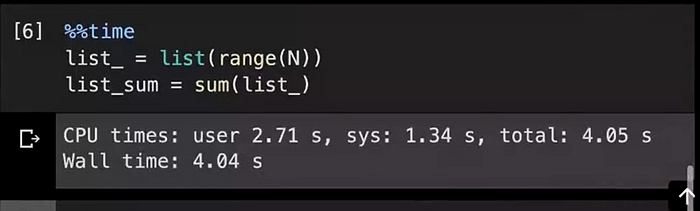
It is much faster, again we get almost 3x improvement in time if we use the in-built ‘sum()’ function.
Let’s do the same operations in NumPy. First, we import the NumPy package.

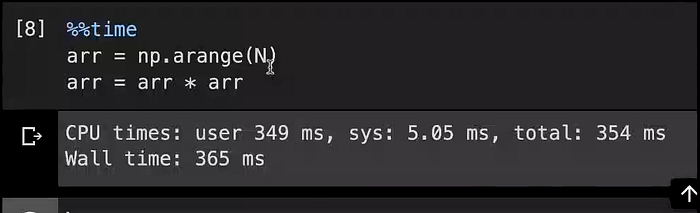
NumPy allows us to write operations like this, the way we square a scalar number, the same syntax can be used to square individual items within the NumPy array. So, ‘arr * arr’ simply goes through each data item no matter what its size is, what its shape is, how many dimensions it has, and performs the operation item-wise.
And this runs in 354 milliseconds, the same N (10⁸ numbers) is being used, and now it’s significantly faster. It’s because of the way NumPy stores this data, the way it iterates over it and the fact that NumPy is implemented in C provides for this boost in performance.
Let’s do the sum() operation in NumPy:
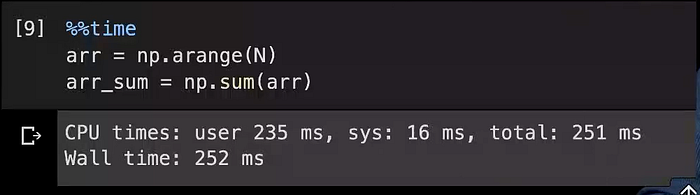
So, it took almost 250 milliseconds to sum up 10⁸ numbers in NumPy.
And it’s also clear from the above two images that it takes lesser time, to sum-up these 10⁸ numbers than multiplication and it shows that it can reach that level of performance that the hardware can natively support.
In this article, we have established by small experiments that NumPy arrays are significantly faster than lists and thereby is a better data structure to store high dimensional data.
References: PadhAI